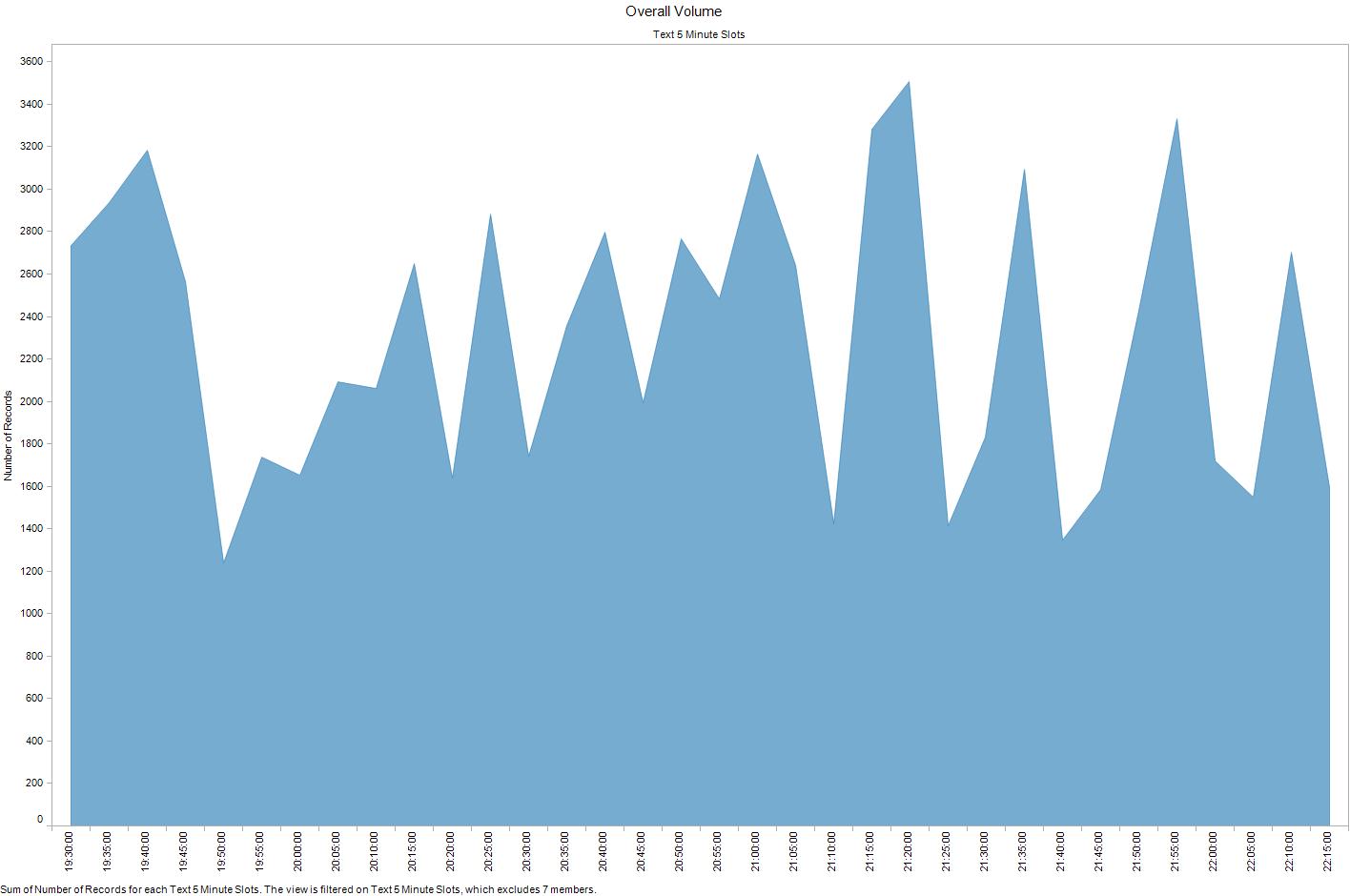
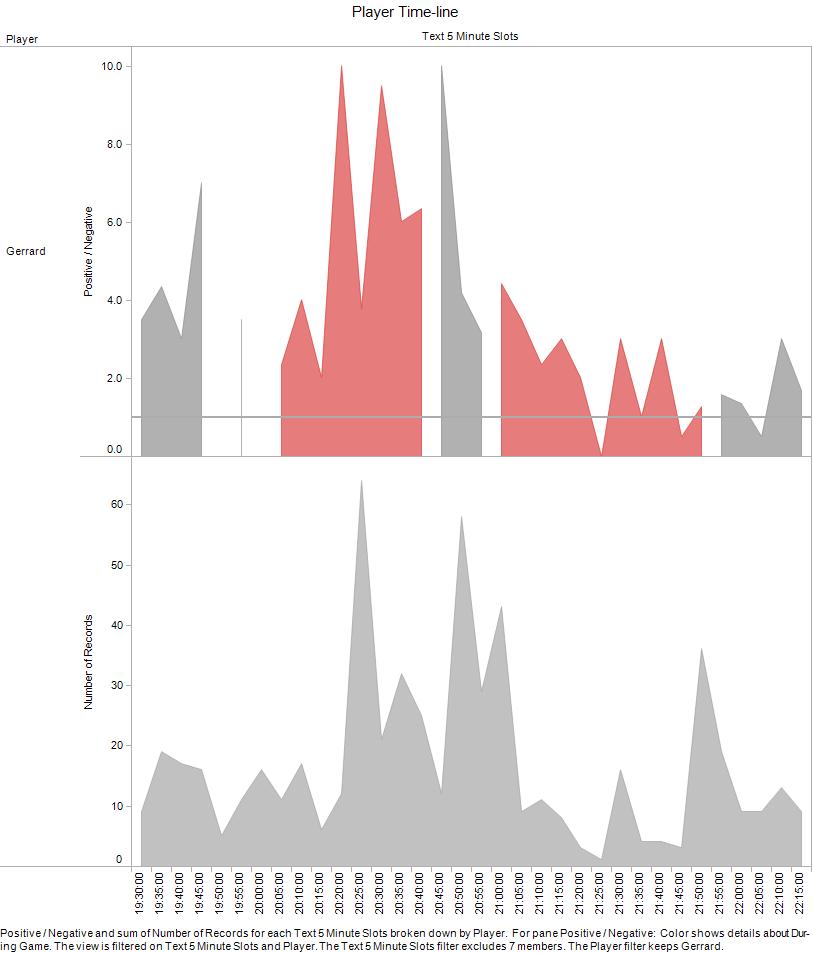
Friday analogy time. Bear with me...
Imagine you're planning a holiday. Or rather, you're deliberately not planning a holiday. You know you want a break from work but you're not sure where you'd like to go, or what you'd like to do.

Imagine also, that you're a marketer who's got very over-excited about the concept of Big Data.
So here's what you do.
You buy some really big suitcases and pack all the clothes you own into them. After all you don't know if you're going to the beach or the Arctic yet, so you'd better pack everything from Speedos to ski gear.
Will there be accommodation when you get there? We don't know yet. Best put in a tent. Or two, one for summer and one for winter.
And off to the airport, to investigate flights!
In the airport, you realise you also need lots of toiletries and medical supplies for your trip and another suitcase to store them in. You buy most of the stock in Boots and store it in your new suitcase because you still don't know where you're going or what you might need. The mosquito repellent bottle leaks everywhere and Deet is nasty, smelly stuff so you have to buy lots of things twice.
You pick a flight and head off on holiday. The flight was expensive, because you bought the ticket at the airport, rather than in advance. You'll be paying off your excess baggage fees for the next ten years.
Your hotel at the other end is expensive too because you didn't arrange a cheap deal before you left.
Finally, despite your hotel room being stuffed full of suitcases that you didn't need to bring and your bank balance having taken a hammering, you have a really fantastic holiday. A job well done.
You've probably guessed where I'm going with this one, but (not) planning a holiday like that, is pretty much the approach we're taking when we say "let's assemble loads of data and wonderful things will happen."
They might. If you don't run out of money along the way.
But if you decide where you want to go first and then build what you need to get there, you'll build something faster, better, more useful and for a hell of a lot less money.
Big Data is not an end in itself, it's a means to an end. If you don't know where you're going yet, then stop, work that out, and then go looking for what you'll need to get there.
Imagine you're planning a holiday. Or rather, you're deliberately not planning a holiday. You know you want a break from work but you're not sure where you'd like to go, or what you'd like to do.

Imagine also, that you're a marketer who's got very over-excited about the concept of Big Data.
So here's what you do.
You buy some really big suitcases and pack all the clothes you own into them. After all you don't know if you're going to the beach or the Arctic yet, so you'd better pack everything from Speedos to ski gear.
Will there be accommodation when you get there? We don't know yet. Best put in a tent. Or two, one for summer and one for winter.
And off to the airport, to investigate flights!
In the airport, you realise you also need lots of toiletries and medical supplies for your trip and another suitcase to store them in. You buy most of the stock in Boots and store it in your new suitcase because you still don't know where you're going or what you might need. The mosquito repellent bottle leaks everywhere and Deet is nasty, smelly stuff so you have to buy lots of things twice.
You pick a flight and head off on holiday. The flight was expensive, because you bought the ticket at the airport, rather than in advance. You'll be paying off your excess baggage fees for the next ten years.
Your hotel at the other end is expensive too because you didn't arrange a cheap deal before you left.
Finally, despite your hotel room being stuffed full of suitcases that you didn't need to bring and your bank balance having taken a hammering, you have a really fantastic holiday. A job well done.
You've probably guessed where I'm going with this one, but (not) planning a holiday like that, is pretty much the approach we're taking when we say "let's assemble loads of data and wonderful things will happen."
They might. If you don't run out of money along the way.
But if you decide where you want to go first and then build what you need to get there, you'll build something faster, better, more useful and for a hell of a lot less money.
Big Data is not an end in itself, it's a means to an end. If you don't know where you're going yet, then stop, work that out, and then go looking for what you'll need to get there.